Integrate Bigeye with dbt so that you can leverage the strengths of both tools to improve your data analytics and reporting processes. Utilize Bigeye’s dbt Cloud or dbt Core connection guides below or validate your dbt model changes using Bigeye Deltas by navigating to this tutorial.
Connect to dbt Core
Bigeye can accept information from dbt Core job runs in two ways: via the Airflow operator, or via the Bigeye CLI.
If you run dbt Core through Airflow, follow our Airflow instructions to add the Bigeye dbt Core Operator to your DAG.
If you do not use Airflow to run dbt Core, you can follow our CLI instructions to install the Bigeye CLI in your environment. Then, whenever you run dbt you can run this command to send the job run information to Bigeye: bigeye catalog ingest-dbt-core-run-info --workspace staging --target_path ~/repos/dbt_testing/target --job_name dbt_testing_job
Connect to dbt Cloud
Integrating dbt Cloud with Bigeye allows you to access dbt Cloud jobs and their corresponding job runs seamlessly. These jobs are responsible for updating tables within your data pipelines and identifying the underlying issues related to pipeline reliability, data quality, and shifts in business metrics.
Prerequisites
Before connecting dbt Cloud to Bigeye, create a dedicated service user in dbt Cloud for Bigeye. Bigeye uses this account to read metadata for all dbt jobs and dbt job runs. Provide read-only access to limit the jobs that Bigeye can see.
To connect to dbt Cloud, follow these steps:
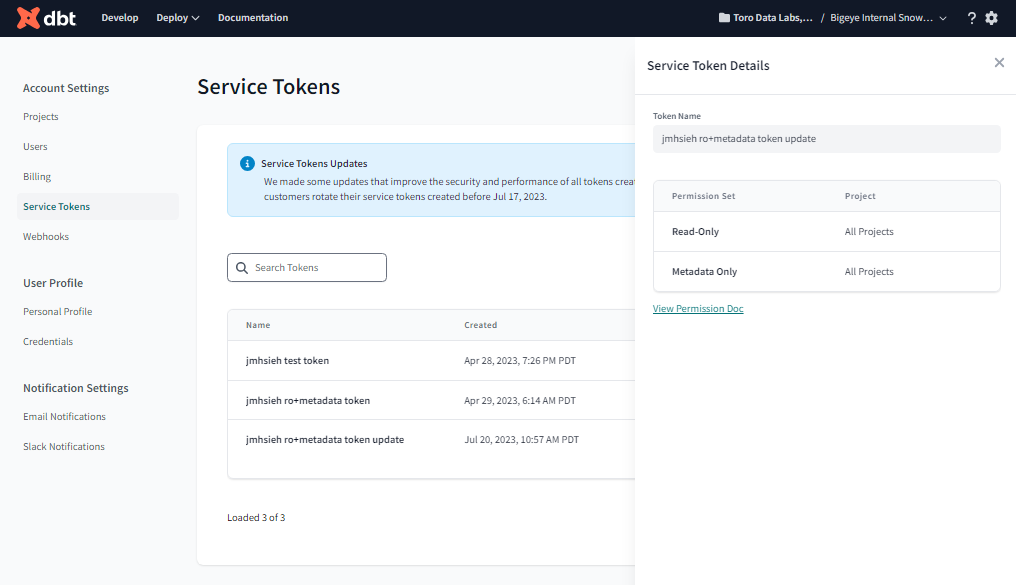
- Select the dbt Cloud user, and then go to Account Settings > Service Tokens to generate a dbt Cloud access token. See Service Account Tokens in dbt Cloud documentation for additional details.
Your service user must have metadata and read-only permissions to the dbt cloud account.
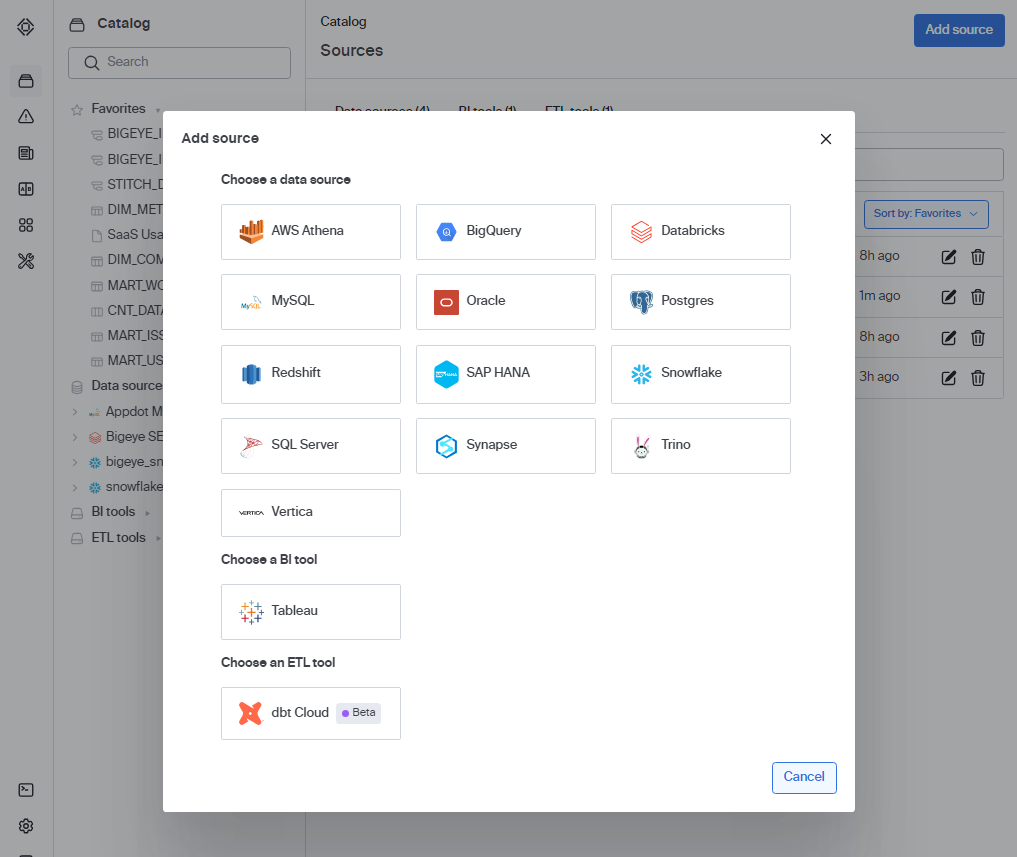
- Add dbt Cloud as an ETL tool in Bigeye. From the Catalog page in Bigeye, click Add source. You can now see a menu of different sources for metadata and data. Choose dbt Cloud from the Choose an ETL tool section to set up your dbt Cloud connection.
- On the dbt Cloud Add Source modal, enter the following information:
- Enter the Name that you want for the dbt Cloud account in Bigeye.
- Enter the personal access API token for Bigeye’s dbt Cloud service user. Copy and paste the token that you generated in Step 1.
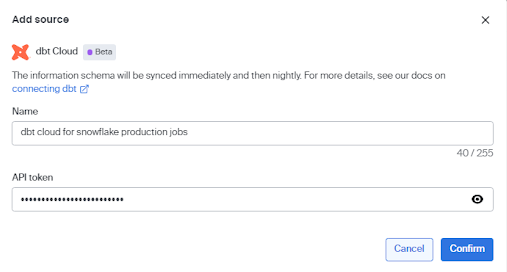
- Click Confirm.
The Bigeye workspace is now connected to the dbt cloud. Click the ETL tools tab to view the different dbt projects and job counts.
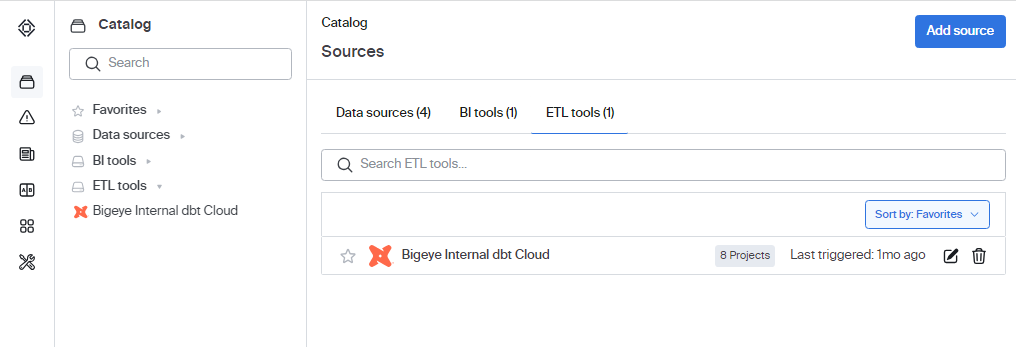
- Click the name of the dbt Cloud project to view the dbt Cloud jobs. The View in dbt link next to the job name takes you to the related dbt Cloud job pages.
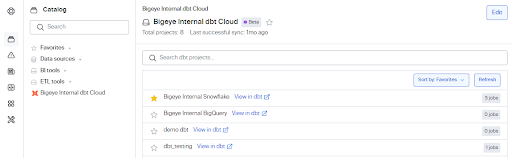
You can only view the dbt Cloud jobs that Bigeye has access to. If no jobs are displayed after clicking Confirm, try to add the dbt Cloud source again, or verify your credentials.
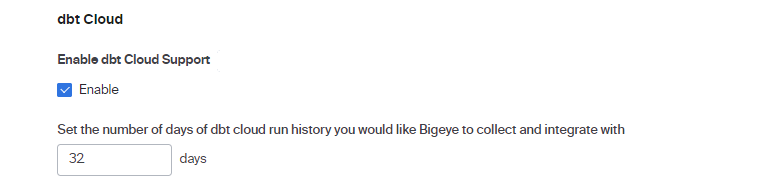
When you connect to dbt Cloud Source, we query job status every 12 hours and the default number of days of dbt job history that Bigeye can collect and integrate with is 32 days. Any issues earlier than that do not have links to preceding issues in dbt Cloud jobs. To extend the days in the dbt Cloud job run history, navigate to Advanced Settings > dbt Cloud and change the number of days as shown in the following image:
Delete a dbt Cloud connection
To delete a dbt Cloud connection:
- Navigate to the dbt Cloud page and click Edit in the upper right corner of the page.
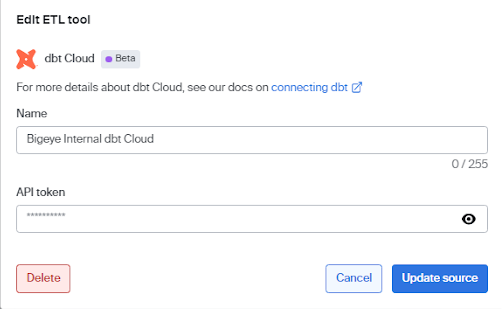
- Click Delete on the Edit ETL tool modal, and then click Confirm to delete the dbt Cloud connection.
View your dbt projects in the Catalog
Bigeye integration with dbt setup enables the following capabilities:
- Catalog integration
- Root cause analysis
Catalog integration with dbt
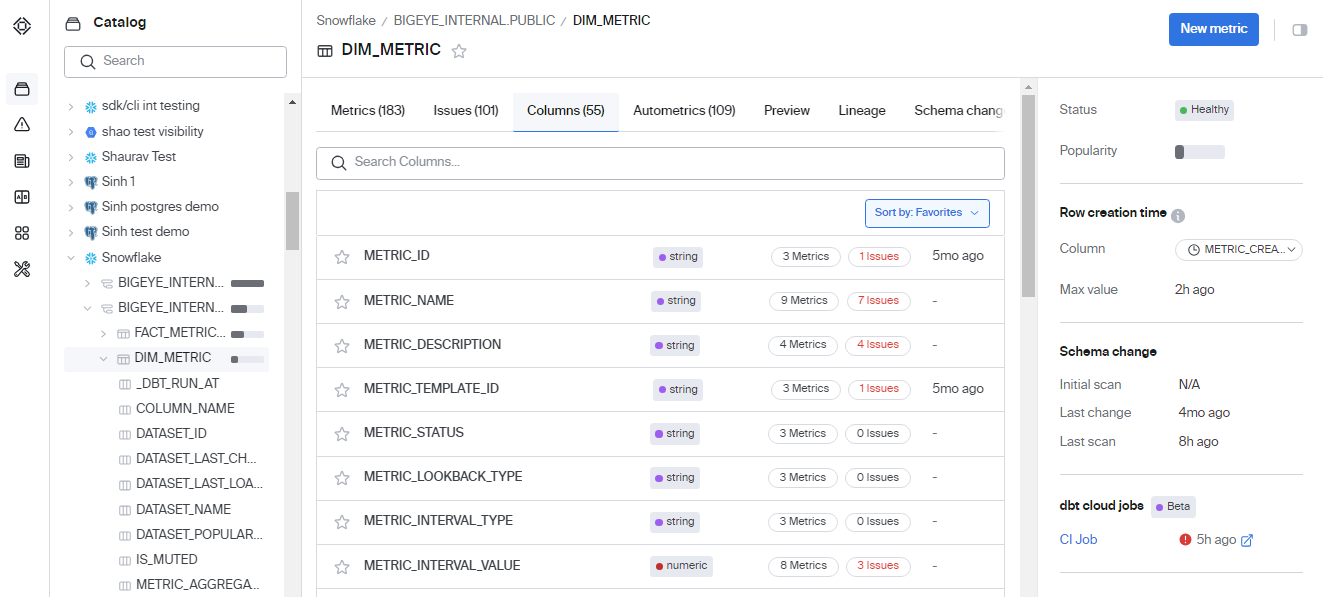
dbt integration with Bigeye connects different schemas, tables, and columns to their respective dbt jobs. The job updates data values in tables and identifies any issues created due to a dbt job run.
You can view the dbt updated tables, schemas, or columns on the Catalog page. The additional metadata about the dbt job connects you to the last dbt job run and displays its status. The right panel has a link to the dbt job that you can use for further debugging.
The color of the circle just next to the job link represents the status of the last dbt job run. The red color indicates that the job failed, while the green color indicates that the job was successful.
Root cause analysis with dbt integration
Use dbt metadata displayed on the Catalog page corresponding to dbt updated or created tables to get additional information on the dbt job. The direct link from the catalog page to the dbt job helps in the root cause analysis process. You can also know the time of the last job run and if it was successful.
In cases of pipeline reliability issues, such as data freshness or volume, the failed dbt job runs are often indicative of potential root causes for the issue. For data quality metrics and value changes, successful job runs might mask underlying issues in the dbt code or problems with upstream data sources. Providing these links empowers data engineers to trace the connections and identify the fundamental reasons behind the issue.
Example cases and potential diagnoses:
- Alerting freshness/volume metrics on the dbt table + failed dbt job
- dbt service outage
- Bad dbt repo commit broke the dbt job
- Alerting freshness metrics on the dbt table + successful but stale dbt job
- Table removed/renamed from dbt job but not DW
- Alerting volume metrics on the dbt table + successful dbt job
- Ingest upstream from dbt job has failed or has been disabled
- Alerting distribution metrics on the dbt table + successful dbt job
- Dbt code change (bug or intentional)
- Changed data characteristics of data upstream from dbt
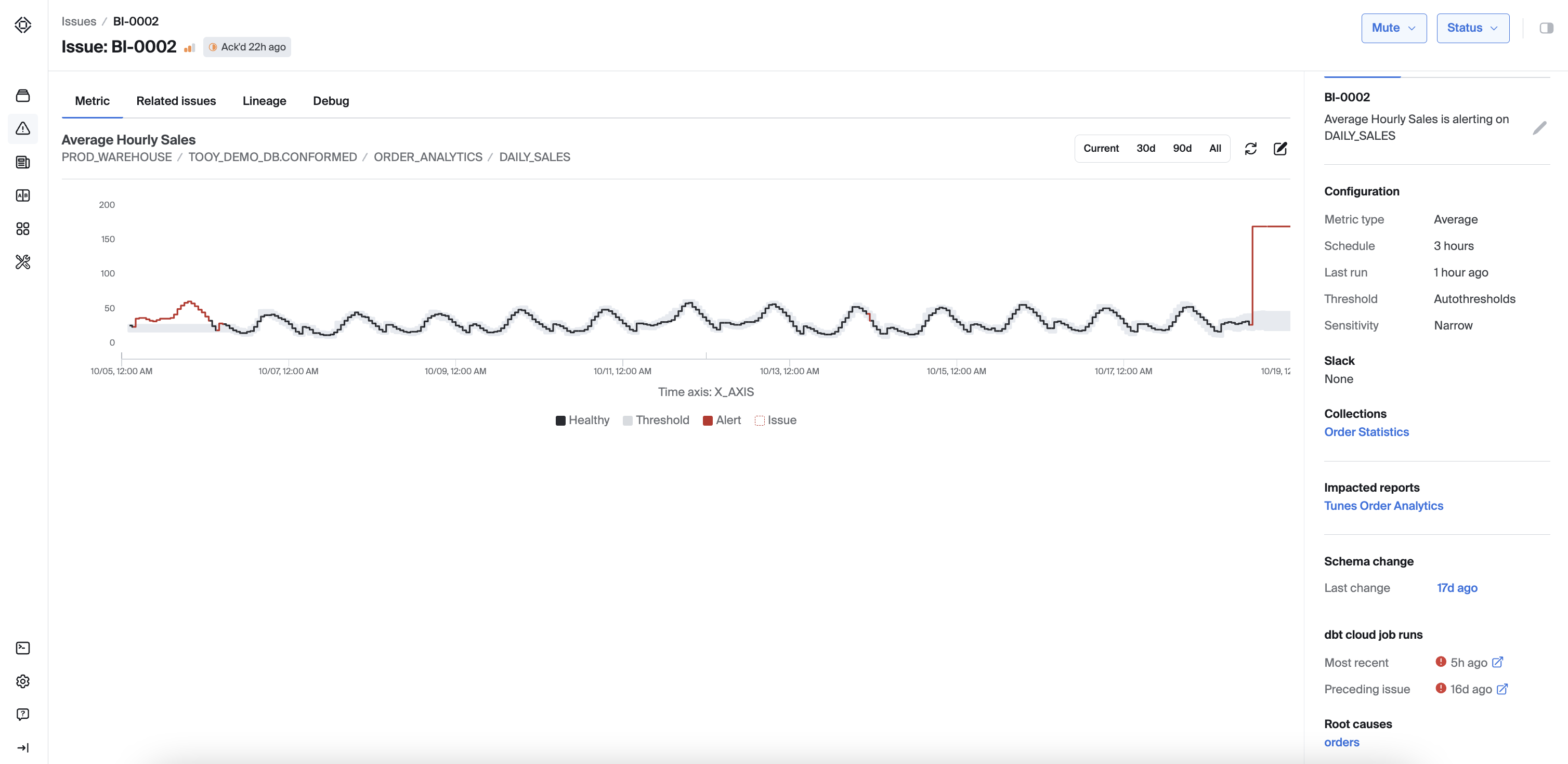
Example
Bigeye will show you the preceding job and most recent job status.
Preceding job ensures you know how dbt ran right before the issue occured no matter when you look at the issue.
Most recent job ensures you can check that current runs are healthy which can help you triage and close the issue.
Updated over 1 year ago