
Join Rules
Validate data consistency across multiple tables and even across different data sources
Overview
These rules enable you to create custom SQL logic that joins tables together and evaluates data quality conditions based on the joined results.
What Are Join Rules?
Join Rules are custom data quality rules that:
- Join two tables together based on one to many sets of specified key columns
- Apply custom SQL logic to validate data values at the row level across the joined tables
- Support cross-source validation (joining tables from different databases/warehouses)
- Provide detailed monitoring and alerting for data consistency issues based on a manually set threshold
Required Setup – Cross-source Agent
Join Rules require a cross-source agent installed on your infrastructure. This agent enables joins between tables in different data sources. The rules are applied to a table created outside both sources, which the cross-source agent hosts and manages.
Networking and Configuration
The networking requirements and YAML configuration for the cross-source agent are the same as those for data-source agents used in Bigeye.
Hardware Requirements
You can run the cross-source agent and the data-source agent on the same server. The cross-source agent requires sufficient memory and disk space (recommended: 32GB of memory and 200 GB disk space on /var). Resource needs depend on table size, join complexity, and the number of concurrently running join rules. Each join rule can consume a max of 1GB of memory, and anything in excess will be written to /var. Allocate memory and disk capacity and adjust concurrency appropriate for your workload. Increasing memory allocation allows more concurrency when running Join Rules.
Overall, the cross-source agent has different hardware requirements due to different underlying query patterns: the cross source agent will load the data from the source tables and perform the join in memory, temporarily writing anything in excess of 1GB to disk, whereas the data-source agent typically runs aggregate queries on a single database.
How to Create Join Rules
Step 1: Create a Join
- Navigate to to the catalog and to the table level of a source which is included on the cross-source agent
- In the right hand pane of the table level page of the catalog you will find a Join section where you can click "+ Add join"
- Your left table of the join will be the table which is represented on the catalog page where you initiated the join creation, the right table can then be selected from your catalog by typing in the table name in the field entry. Note that your right table must also be included in the cross-source agent. Click Next.
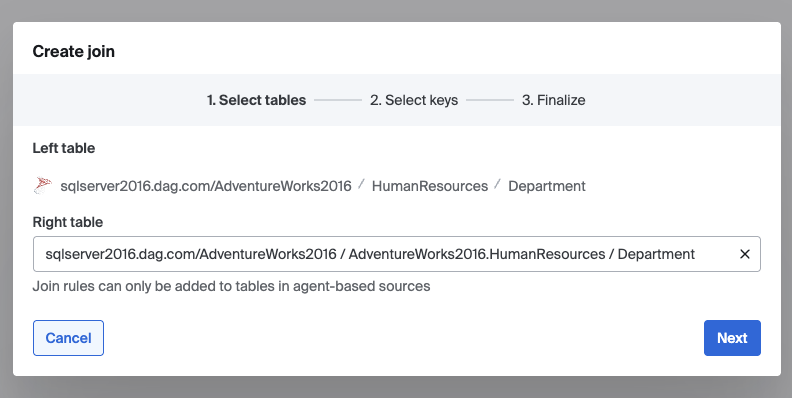
- Select the columns in each of the tables that will be used for joining. You can select one to many key columns. Click Next.
- Then select your filtering option and proceed with the Create Join button.
- You will now be able to find your join in the right hand pane of the catalog pages for each of the joined tables.
Step 2: Create Rule
- Navigate to the Add monitoring modal and select "Join rule"
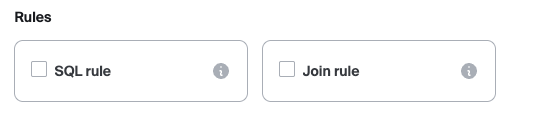
- Select the Join you would like to use for the rule. Zero to many rules can be created for a given join.
- Choose your join configuration, inner, left, right, or full.
- Select all the columns that will be involved in your SQL conditions.
- Next name the rule, give it a description, add aliases to the tables (to reference in your SQL), write your SQL condition, and then define the threshold.
- Finally, select the Data Dimension that your rule will be reported under and define the schedule for the rule. Click "Create rule"
Key Features
Cross-Source Support
Join Rules support single source joins, cross-source joins, and joins involving virtual tables.
Join Types
You can configure your individual rules to use the join in the following configurations:
- LEFT JOIN: Include all records from the left table
- RIGHT JOIN: Include all records from the right table
- INNER JOIN: Include only matching records from both tables
- FULL OUTER JOIN: Include all records from both tables
The join you choose will affect the results of the rule.
Flexible Column Selection
Select Specific Columns, choose which columns to include from each join, fewer columns selected will result in faster executions.
A common mistake is to forget to select a column that you end up using in your rule's SQL
Advanced Filtering
Filtering your tables helps the cross-source agent run your joins efficiently, apply a filter whenever possible. You can apply filters on either of the tables in the join in the following ways:
- Rolling Time Window: Select a date column and then a lookback (in days). This includes only rows within a time window, with the lookback starting from the max value in the row creation time column.
- Filter Condition: Apply a custom WHERE clause to your tables before the join occurs.
Common Use Cases
1. Data Consistency Validation
-- Validate that customer IDs exist in both systems
left.customer_id = right.customer_id AND right.customer_id IS NOT NULL2. Reference Data Validation
-- Ensure all product codes are valid
left.product_code = right.code AND right.is_active = true3. Cross-Source Data Integrity
-- Validate financial transactions across systems
left.transaction_amount = right.amount AND
ABS(left.transaction_amount - right.amount) < 0.014. Completeness Checks
-- Ensure required fields are populated
(right.required_field IS NOT NULL) OR (left.optional_flag = 'Y')5. Business Rule Validation
-- Validate business logic across systems
CASE
WHEN left.customer_type = 'PREMIUM'
THEN right.discount_rate >= 0.1
ELSE right.discount_rate >= 0.05
ENDBest Practices
Performance Optimization
- Use Indexed Columns: Join on indexed columns for better performance
- Apply Filters Early: Use table-level filters to reduce data volume before joining
- Monitor Resource Usage: Track query execution time and resource consumption
Rule Design
- Clear Naming: Use descriptive names that explain the validation purpose
- Comprehensive Documentation: Add detailed descriptions for complex rules
- Error Handling: Account for NULL values and edge cases in your SQL logic
Cross-Source Considerations
- Network Latency: Consider network overhead when joining across sources
- Data Freshness: Account for potential data synchronization delays
Conclusion
Join Rules provide a powerful mechanism for ensuring data quality across multiple tables and data sources. By leveraging Bigeye's comprehensive join rule functionality, you can create sophisticated data validation logic that maintains data integrity and consistency across your entire data ecosystem.
Updated 9 months ago