
Data Profiling
Quickly understand the contents of your data and identify the right monitoring to apply.
Overview
Data profiling helps you understand the contents of a table, as well as what monitoring should be applied to ensure data quality over time.
Using the Profile tab in Bigeye you'll get:
- Table-level profile rendered as a sortable grid (columns = profile dimensions, rows = your table’s columns)
- Safe-by-default execution (no raw values persisted; only aggregates and anonymized outputs)
- CSV export of the full profile for easy sharing
- bigAI generated monitoring suggestions you can deploy with a click
- Direct link to the profile from the metric deploy flow (opens in a new tab)
Enable Profiling
Direct connect customers do not need to do anything to setup profiling. Agent-based customers must have version 2.6.0 or later in order to support data profiling.
Because data profiling is a memory-intensive operation, soft and hard caps have been implemented in the feature to protect underlying infrastructure. You will notice that only part of your configured sample will be profiled when a soft or hard cap is hit. For agent-based customers, If more rows of data are needed for your profiling operation, more memory should be added to the supporting infrastructure. For direct connect customers, please reach out to your Bigeye representative if you are unable to run your desired sample sizes.
- Soft cap: the profiling engine has used 10% of allocatable memory. If your JVM has 100 MB of memory, the profile will cap at 10 MB. Runtime.getRuntime().maxMemory() is used as the basis for this calculation.
- Hard cap: This is the safety net for the soft cap, if for some reason the system does not recognize or respect the 10% rule the engine will cap at 10 million rows of data.
Profile a table
- Open the Catalog and navigate to a table.
- Click the Profile tab.
- Click Run profile
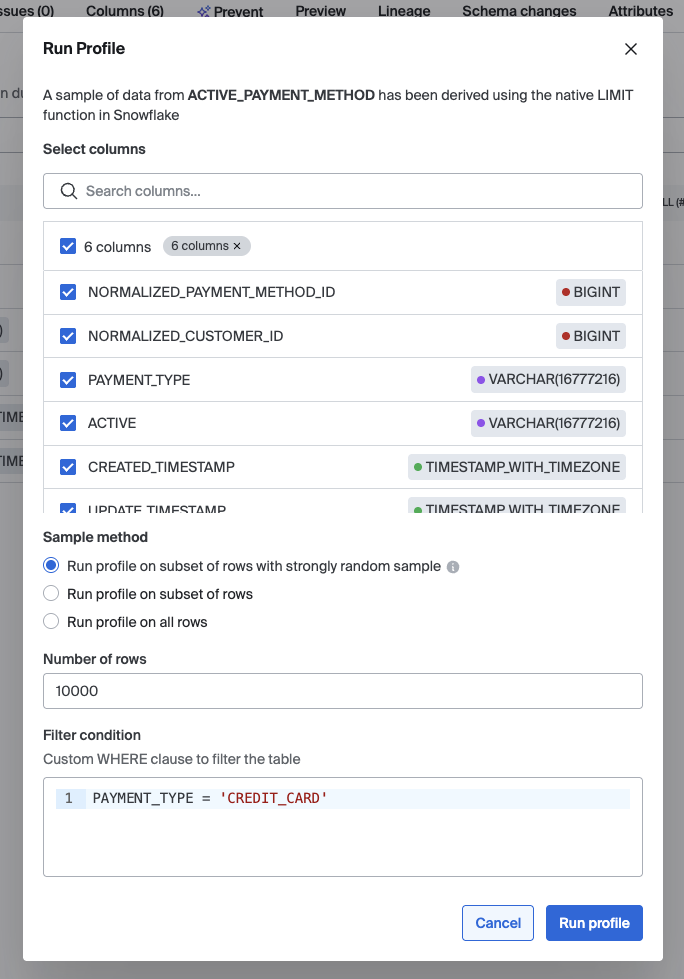
- In the Profile Configuration modal:
- Columns: Select the columns you would like to have included in the profile.
- Sample method:
- Run profile on subset of rows with strongly random sample - this option uses more complex computation of the random sample to provide a higher randomness. This option will increase the processing time of the profile.
- Run profile on subset of rows - this option will use a static
LIMIT(noORDER BY); and results reflect the first N returned rows. - Run profile on all rows - this is the most thorough but for large tables, expect this to take a long time to process
- Number of Rows: if sampling was chosen, this determines the number of rows in the sample
- Filter condition: this filters the set of data to be profiled before the sample is taken. Example where clause, PAYMENT_TYPE = 'CREDIT_CARD'
- Click Run profile. The profile will process for some time depending on the configuration you have selected.
- Review the Profile output.
- (Optional) Click Export CSV to download the profile output table.
- (Optional) Use View suggestions or the suggestion drop downs in the output table to deploy bigAI suggested monitors.
You can re-run a profile any time. Configuration settings persist for the table, so subsequent runs start with your last-used settings.
Profiling Results
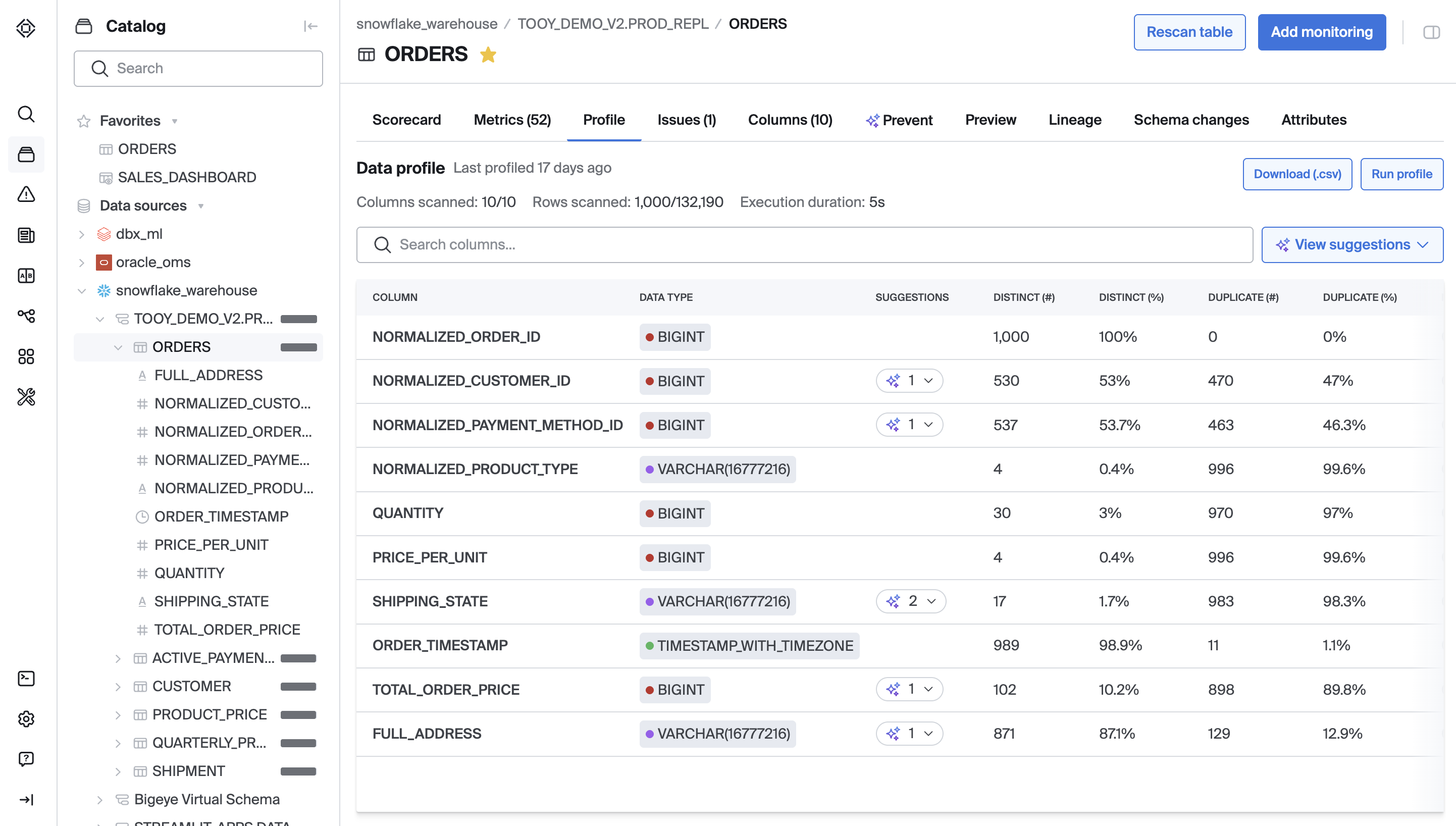
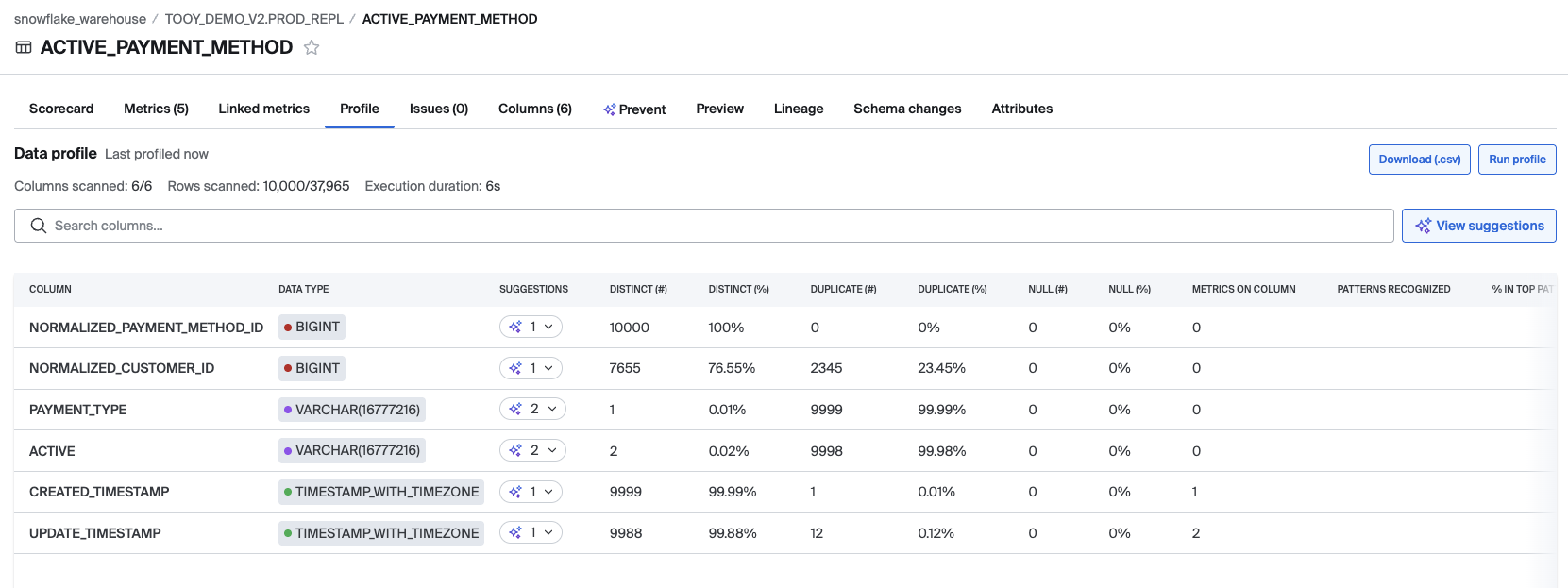
Profile outputs always show only the results from the most recently run profile. Each table column appears as a row in the Profile Grid, with the following dimensions (left-to-right):
- Data type — Highest granularity (e.g.,
varchar(32210)). - Distinct # / % — Count and percent of distinct values within the scanned sample.
- Duplicates #/% — Count and percent of duplicate values found in the sample.
- Nulls # / % — Count and percent of nulls.
- Metrics on column — Number of existing metrics attached to the column. Does not account for SQL Rules, Deltas, Join Rules, etc., only metrics.
- Top Pattern recognized — The most common pattern that was recognized in the sample for string-like columns.
- % in top pattern — Share of values matching the most common recognized pattern. The pattern recognized will be named, e.g., "Email", "SSN", etc.
- Min char length — Minimum character length found in the sample for string-like columns; N/A otherwise.
- Max char length — Maximum character length found in the sample for string-like columns; N/A otherwise.
Pattern Recognition
- Recognized examples: Timestamp, U.S. ZIP code, U.S. state, Email, Date, Social Security Number, and UUID.
Exporting
- Click Export CSV to download the full profile output grid.
Tip: Teams often annotate the CSV and share it with collaborators who don’t have Bigeye access.
Monitor Suggestions
After a profile run, Bigeye surfaces bigAI-generated and algorithmic suggestions that can be deployed quickly.
Deploying suggestions
- Use Add Monitoring at the table level, or deploy suggestions at the column level.
- You can Deploy all suggestions for a table.
- After deploying metrics, you will see the metrics on columns output update (note that deployment of SQL Rules will not affect this count).
Security, Permissions, and Cost
Safety and Security Guardrails
- To prevent inferring information about individual rows via overly selective filters, Bigeye enforces a minimum rows to profile (default: 100). This setting is managed by Bigeye and can be adjusted by request.
- No raw values are persisted by Bigeye; for agent-based customers, all profiling occurs in your environment.
- No raw data values are persisted with the profile—only aggregates/anonymized outputs (e.g., counts, lengths, percentages).
Permissions & Cost Controls
- Users must have a specific permission that governs who can run profiles.
- Admins always have the permission.
- Manage and Edit roles have it by default (can be revoked if needed).
- All users can always view results in the catalog from a profile no matter their permissions.
- To respect warehouse spend, profiles run only on demand. There are no automatic or scheduled runs.
- Profiles are optimized for speed. Use the default sample size for quickest results.

FAQs
Can I schedule profiles?
Not in this iteration. Profiles run on demand to control warehouse costs.
Do profiles use all rows?
You choose. Use the default sample size for quick scans, or select Full table for comprehensive runs.
Can I filter to a subset (e.g., country = 'US')?
Yes, use the WHERE clause filtering function for this.
What exactly is saved?
Only aggregated/anonymized results and profile metadata (timestamps, generator, configuration). No raw values are stored.
How are bigAI suggestions created?
Suggestions are based on the data profile pulled and in some cases the raw data (if bigAI is allowed). bigAI analyzes correlated columns, regex patterns, statistical measures, and other heuristics to create the suggestions.
If I have disallowed row-level access to bigAI, what will happen to my bigAI generated suggestions?
Disabling bigAI row level data access only removes the LLM-based cross-column correlation suggestions. Everything else continues to work normally because those suggestions are derived from aggregated profile statistics, not raw row data.
Updated 5 months ago